






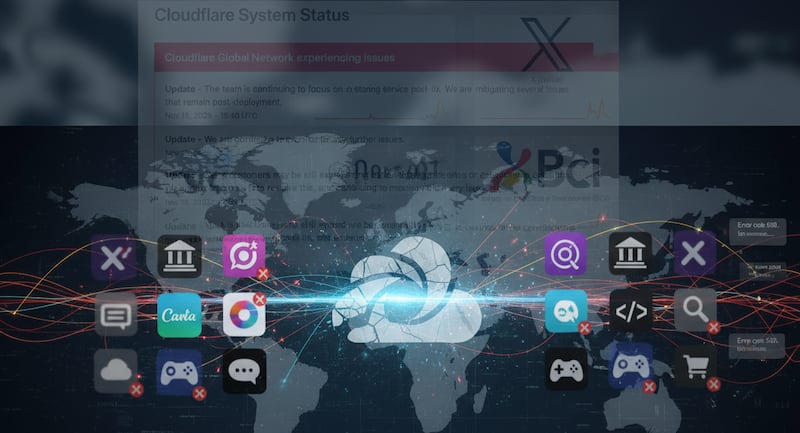
El proveedor de infraestructura de Internet Cloudflare, cuya caída masiva del martes 18 de noviembre afectó a servicios esenciales como X (antes Twitter), ChatGPT, Canva y League of Legends, ha declarado que el incidente está resuelto y que sus servicios operan con normalidad.
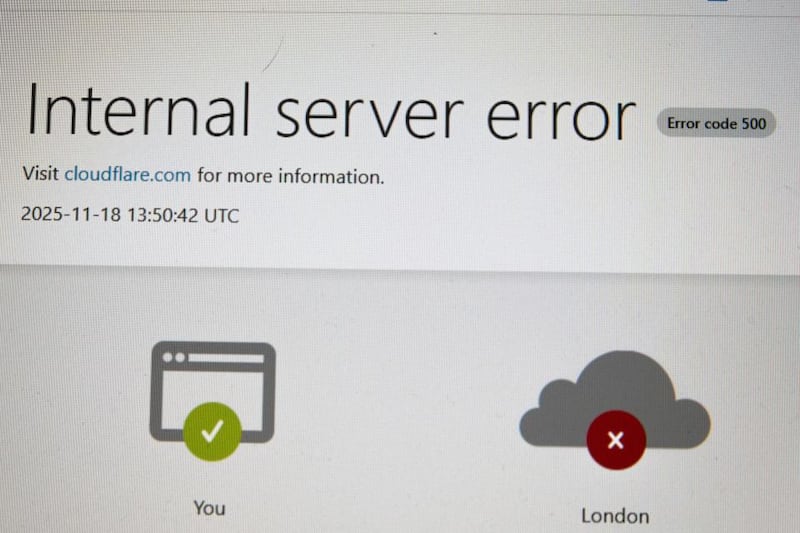
La compañía reportó que a las 17:06 UTC (aproximadamente a las 14:06 hora de Chile) de ayer, el volumen de códigos de error 5xx (fallos del servidor) volvió a los niveles normales.
Lee también: Windows 11 se vuelve Skynet: El primer paso de Microsoft hacia la Computación Agentiva Real
La causa de la caída: No fue un ataque, sino un “Bug Latente”
Cloudflare ha sido transparente sobre la causa del problema, descartando que se tratara de un ciberataque. La interrupción se debió a un “archivo de configuración automatizado” que, a raíz de un cambio de configuración de rutina, creció más allá del tamaño esperado.
El director de tecnología de Cloudflare, Dane Knecht, explicó que el problema se originó por un “bug latente” (un error oculto en el código que no se detecta hasta que se dan condiciones específicas) en un servicio que gestiona las capacidades de mitigación de bots. Este error hizo que el sistema fallara.
El fallo en este sistema interno se propagó, llevando a una degradación masiva de la red y afectando a sus servicios clave como Access, Workers KV y el Panel de Control.
Estado Actual (Miércoles 19 de Noviembre)
- Servicios Normales: Cloudflare afirma que sus servicios están operando actualmente con normalidad, y ya no están observando errores elevados o latencia en la red.
- Vigilancia: Los equipos de ingeniería siguen monitorizando de cerca la plataforma y realizando una investigación más profunda, pero el incidente se da por cerrado.
- Servicios Deshabilitados: Los servicios que fueron temporalmente deshabilitados o en los que se revirtieron configuraciones (como el acceso WARP en algunas regiones) ya se consideran seguros para ser re-habilitados.
En resumen, la espina dorsal de una gran parte de Internet se recuperó del colapso de ayer, pero la causa del fallo—un simple archivo de configuración que creció demasiado—subraya la fragilidad de la infraestructura global ante errores internos.
¿Por qué fue tan impactante?
El backbone de gran parte de Internet acaba de recuperarse de un colapso masivo que tumbó a servicios clave como X (antes Twitter), ChatGPT y plataformas de gaming. Tras horas de pánico digital, Cloudflare ha declarado que el incidente está resuelto.
La gran sorpresa no es la recuperación, sino la causa: la fragilidad de la red global no fue expuesta por un sofisticado ciberataque, sino por un “bug latente” que permitió que un archivo de configuración interno creciera hasta un tamaño descontrolado, creando un efecto dominó que afectó a millones de usuarios en todo el mundo. El incidente subraya lo vulnerable que es la infraestructura digital ante el más mínimo error de software.
¿Porqué Cloudflare habla del “Nivel Base” (Baseline) de fallos? ¿Entonces siempre hay fallos?

Por qué el 100% de confiabilidad no existe
En un sistema tan masivo y distribuido globalmente como Cloudflare, Google o Amazon Web Services (AWS), la perfección absoluta es inalcanzable y, de hecho, no es el objetivo.
1. El Nivel Base (El Ruido del Sistema)
El “Nivel Normal” se refiere a las fallas mínimas, esperadas y constantes que ocurren en cualquier red global:
- Errores Locales: Un servidor en Australia falla por un segundo, un cable submarino tiene un microcorte, el router de un usuario en Chile se reinicia.
- Latencia: Las peticiones viajan a velocidades ligeramente diferentes, provocando algunos timeouts o errores 5xx aislados.
- Hardware: Siempre hay un porcentaje de hardware (discos duros, módulos de memoria, etc.) que muere o falla, pero los sistemas de backup lo reemplazan sin que el usuario lo note.
Este Nivel Base de Fallos es extremadamente bajo (a menudo, una fracción de un 0.001% de las peticiones), pero nunca es cero.

2. El objetivo: Las “Cinco Nueves” (99.999%)
En lugar de buscar el 100%, las grandes compañías buscan una métrica llamada “Cinco Nueves” (Five Nines).
| Fiabilidad | Downtime (Por año) |
|---|---|
| 99% | 3 días, 10 horas |
| 99.999% (Cinco Nueves) | 5 minutos, 15 segundos |
El objetivo de Cloudflare (y otras empresas similares) es mantener los fallos dentro de este pequeño margen (los 5 minutos de tiempo de inactividad por año).
3. El contraste: La caída masiva
Durante la caída de ayer, el porcentaje de errores 5xx (fallos del servidor) se disparó desde ese nivel base imperceptible (por ejemplo, 0.0001% de las peticiones) a un nivel de fallo masivo y evidente (que podría haber sido del 5% o 10% de las peticiones en los nodos afectados).
Cuando Cloudflare dice que los fallos volvieron a niveles normales, significa que ese pico masivo se corrigió, y el sistema regresó a esa baja tasa de error constante y aceptada que es intrínseca a operar una red global de miles de servidores. ¿Lo sabías?
Source link